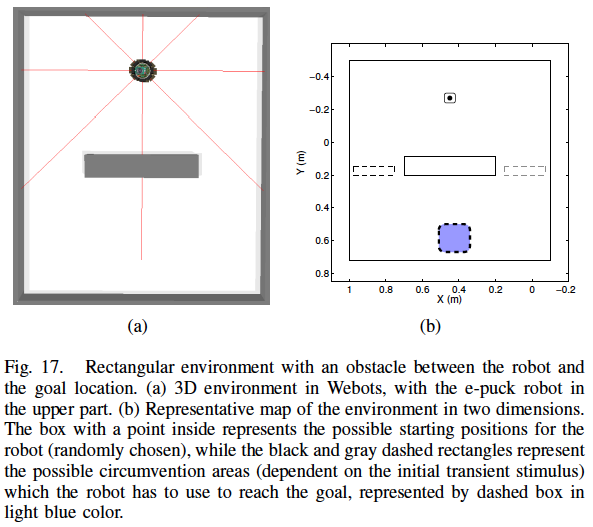
Autonomous robot navigation in partially observable environments is a complex task because the state of the environment can not be completely determined only by the current sensory readings of a robot. This work uses the recently introduced paradigm for training recurrent neural networks (RNNs), called reservoir computing (RC), to model multiple navigation attractors in partially observable environments. In RC, the RNN with randomly generated fixed weights, called reservoir, projects the input into a high-dimensional dynamic space. Only the readout output layer is trained using standard linear regression techniques, and in this work, is used to approximate the state-action value function. By using a policy iteration framework, where an alternating sequence of policy improvement (samples generation from environment interaction) and policy evaluation (network training) steps are performed, the system is able to shape navigation attractors so that, after convergence, the robot follows the correct trajectory towards the goal. The experiments are accomplished using an e-puck robot extended with 8 distance sensors in a rectangular environment with an obstacle between the robot and the target region. The task is to reach the goal through the correct side of the environment, which is indicated by a temporary stimulus previously observed at the beginning of the episode. We show that the reservoir-based system (with short-term memory) can model these navigation attractors, whereas a feedforward network without memory fails to do so.
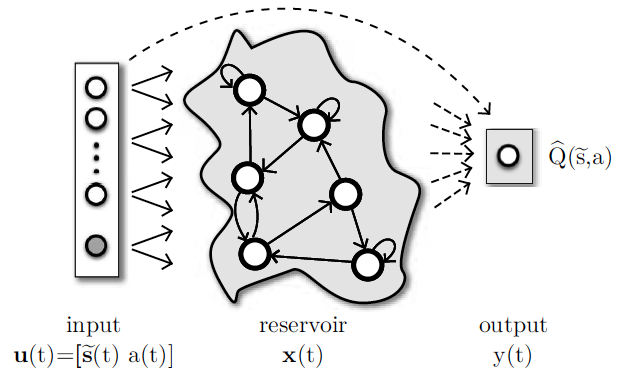
Reservoir Computing network as a function approximator for reinforcement learning tasks with partially observable environments. The reservoir is a dynamical system of recurrent nodes. Solid lines represent connections which are fixed. Dashed lines are the connections to be trained
Motor primitives or basic behaviors: left, forward and right.

A sequence of robot trajectories as learning evolves, using the ESN. Each plot shows robot trajectories in the environment for several episodes during the learning process. In the beginning, exploration is high and several locations are visited by the robot. As the simulation develops, two navigation attractors are formed to the left and to the right so that the agent receives maximal reward.
