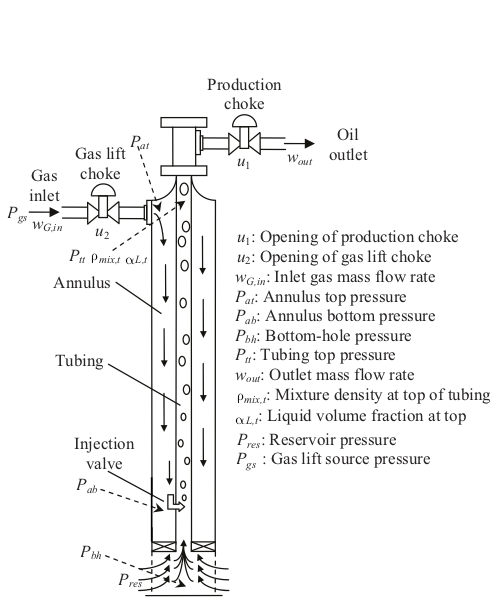
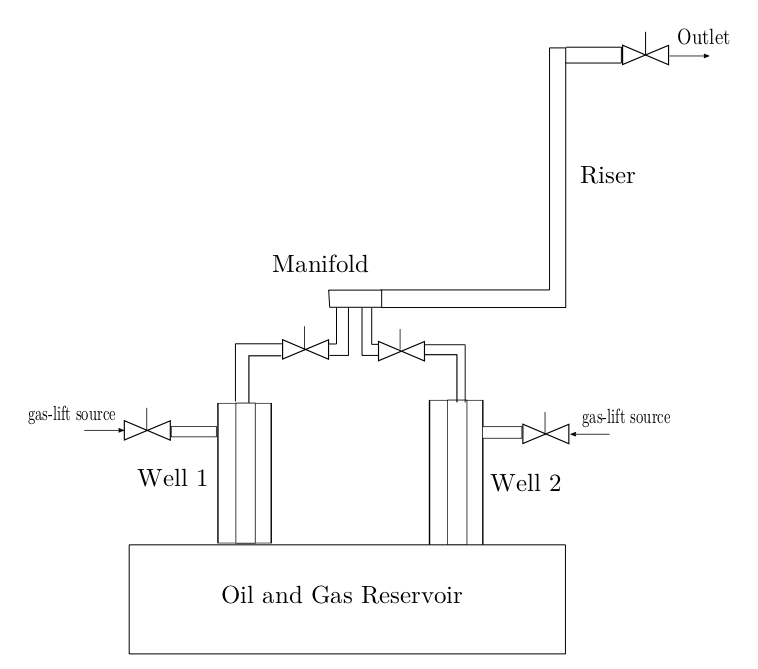
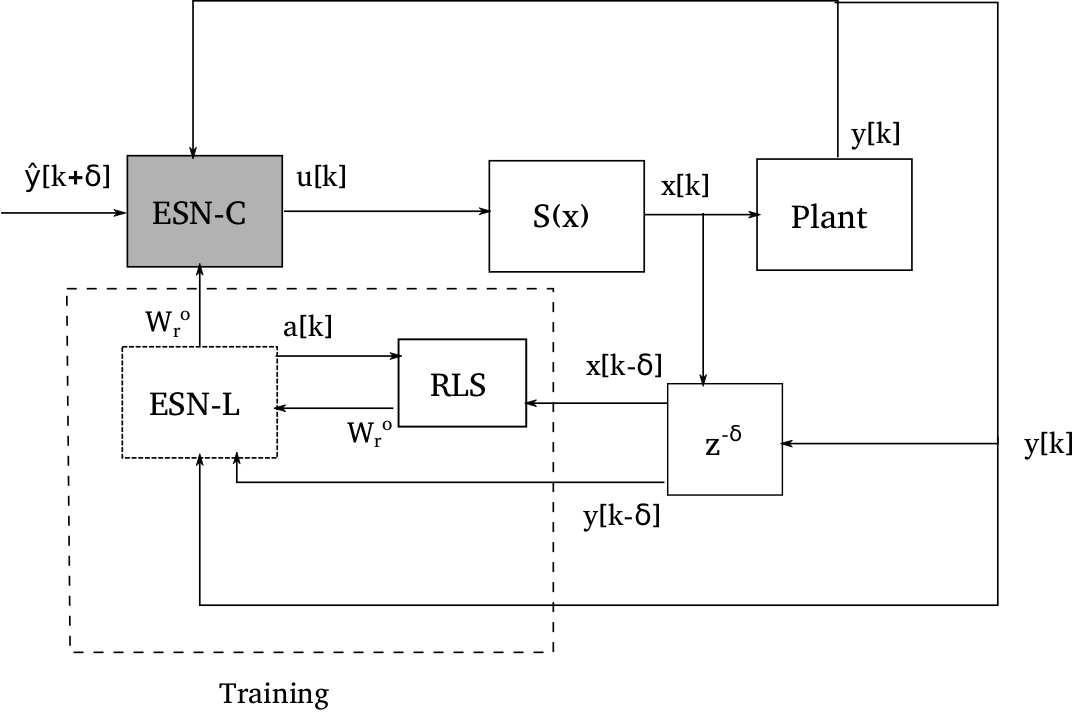
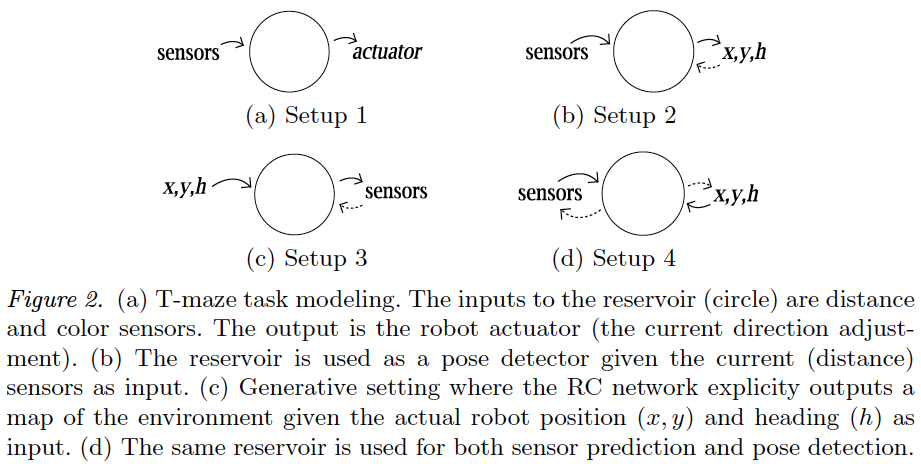
Technologies used: C++, TCP/IP sockets, Linux, Qt, Qwt.
Developed from 2001 to 2010.
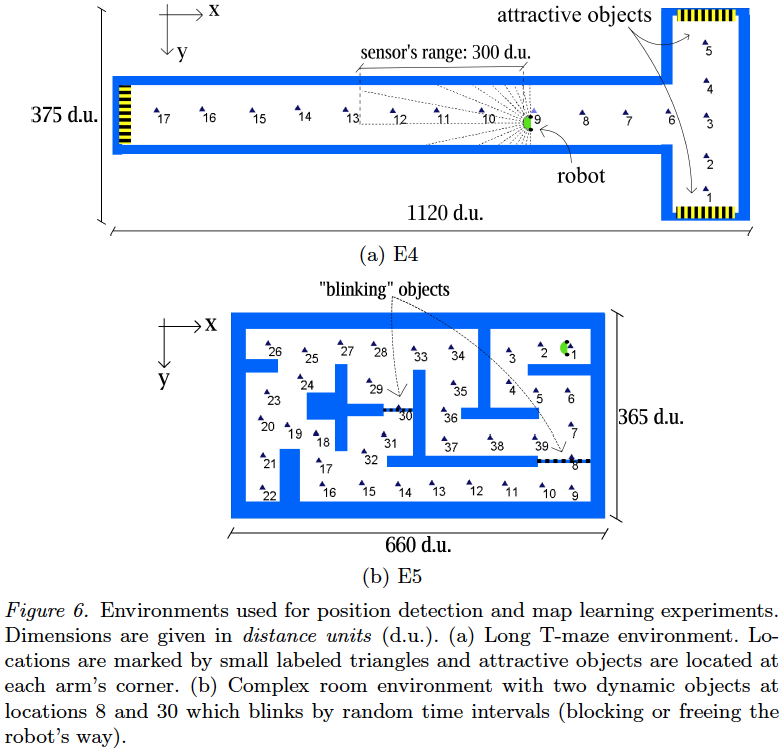
Two different software programs were developed during my undergraduate and Master studies: SINAR, a simulator that shows graphically the representation of the environment and the simulation in real time; and CONAR, the autonomous controller that receives sensor data (from SINAR) and output the actuators data (to SINAR). Simulations with multiple robots can be done if more than one controller (CONAR) connects to SINAR. The communication between both programs is represented on the following figure:
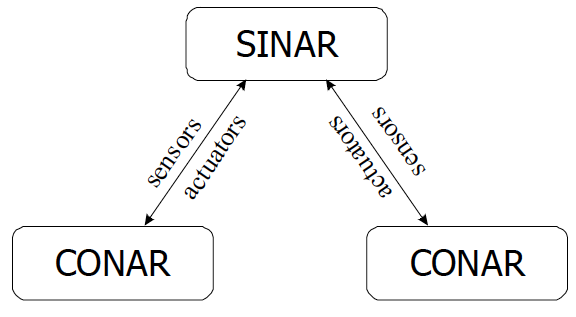
The communication protocol is implemented using TCP/IP sockets. Thus, several controllers can run under different computers over a network (distributing the computing load through different nodes of a network). Both simulator programs were developed under the Linux operating system; the graphical interface was developed with Qt library and some graphical plots were created with Qwt library. C++ was the programming language used to create both programs.
SINAR
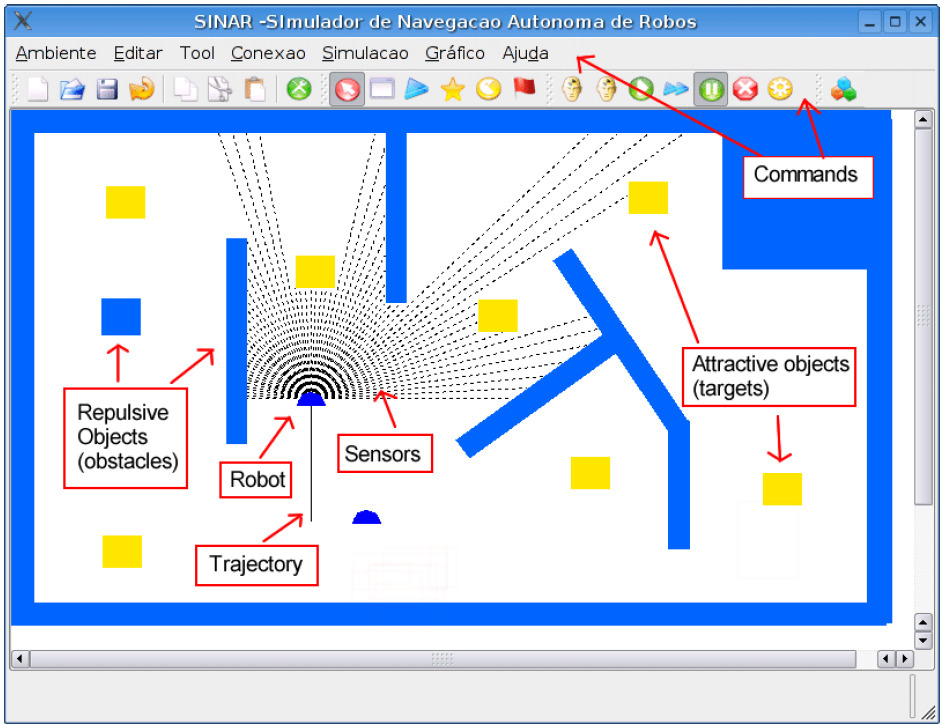
SINAR is a simulator for autonomous robot navigation experiments. Its graphical user interface contains menus, command bars, and the environment display.
The user can create simulation environments merely by clicking and moving the mouse cursor in the display area. Objects are inserted, resized, translated and rotated simply by moving the mouse device. An object can be a obstacle, a target or even a robot. The user can also edit an object by changing its color and type of movement (for moving objects).
Environments can be saved in files and posteriorly they can be loaded for being used in simulations. Before a simulation starts, one or more controllers (CONAR) should be connected to the SINAR software. The user can control the simulation by activating appropriate (button) commands: start, pause and finish.
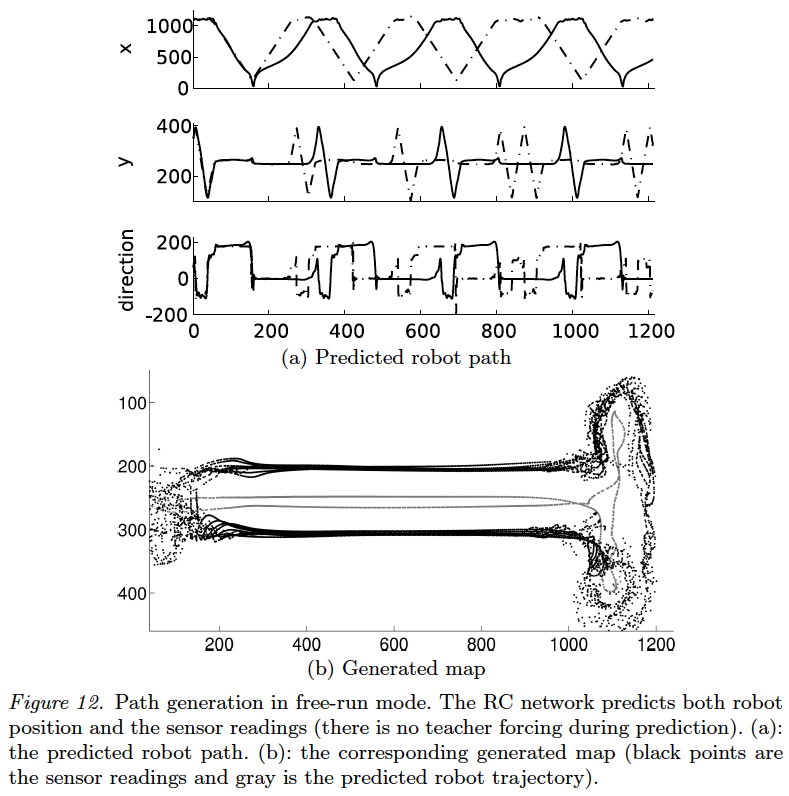
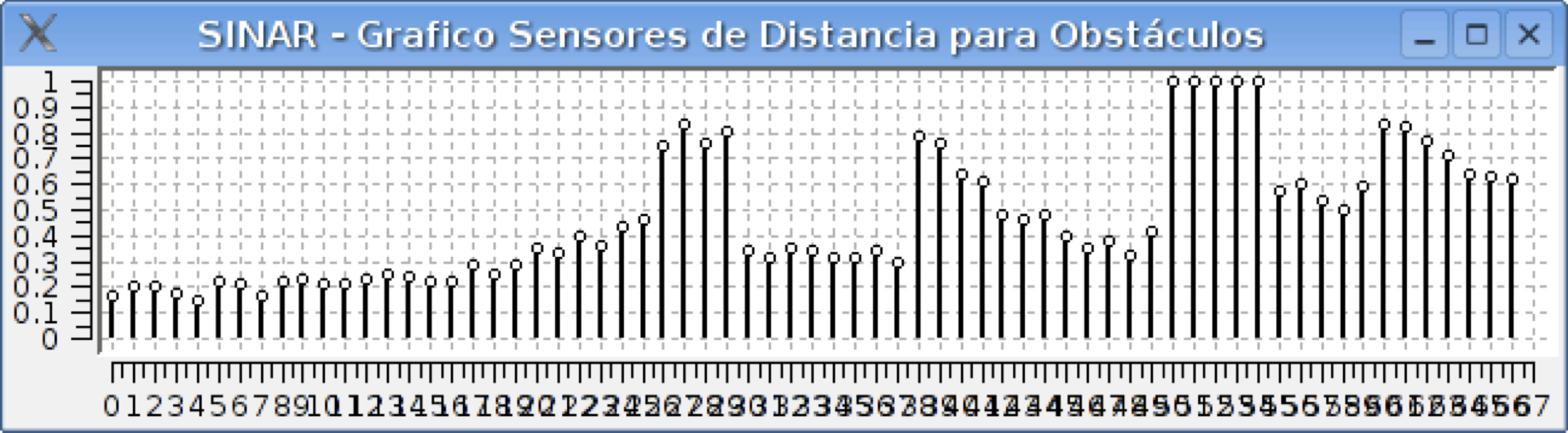
During a simulation, sensor data can be viewed graphically through plots in real time:
The performance of the robot (number of collisions, number of target captures, and number of executed iterations) can be verified in real time as well.
There are two modes of simulation: orginary mode and sophisticated mode. In the former mode, the environment display is updated at each iteration such that the user can view graphically the progress of the simulation. Furthermore, the user can move any object in the environment in real time.
In the latter mode, the simulation is accomplished implicitily (not graphically) and is composed of a set of experiments configured by a specific C++ script. The script determines the sequence and the duration of simulation experiments (considering that each experiment uses distinct environments), besides the number of repetitions for a sequence of experiments. In the sophisticated mode, all generated data are recorded in files: the trajectory of the robot and the performance measures (number of captures, collisions and their respective iteration time); the representation of the final state of the environment in PNG format and the performance plot (also called learning evolution graphic) are also generated automatically. The controller data (neural networks states) are also saved in an automatic way since the script tells CONAR to save its state when each simulation is finished.
CONAR
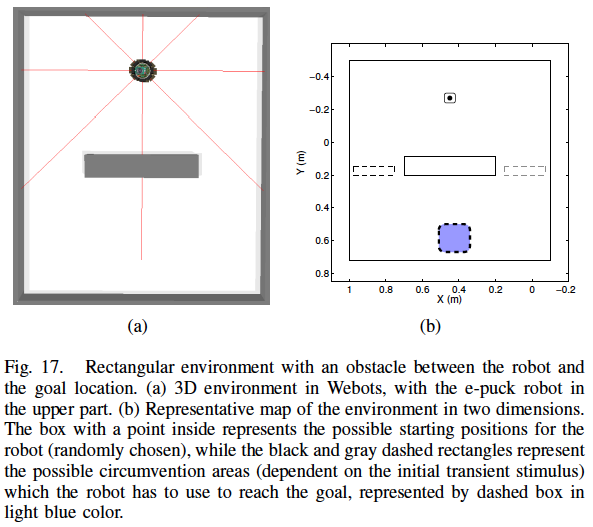
CONAR is a program that simulates the brain of a robot located in the SINAR environment. After receiving sensor data (distance, color and contact) from its respective robot in the SINAR environment, it sends actuator data (direction adjustment and velocity adjustment) to the same robot. This cycle is kept until the simulations ends.
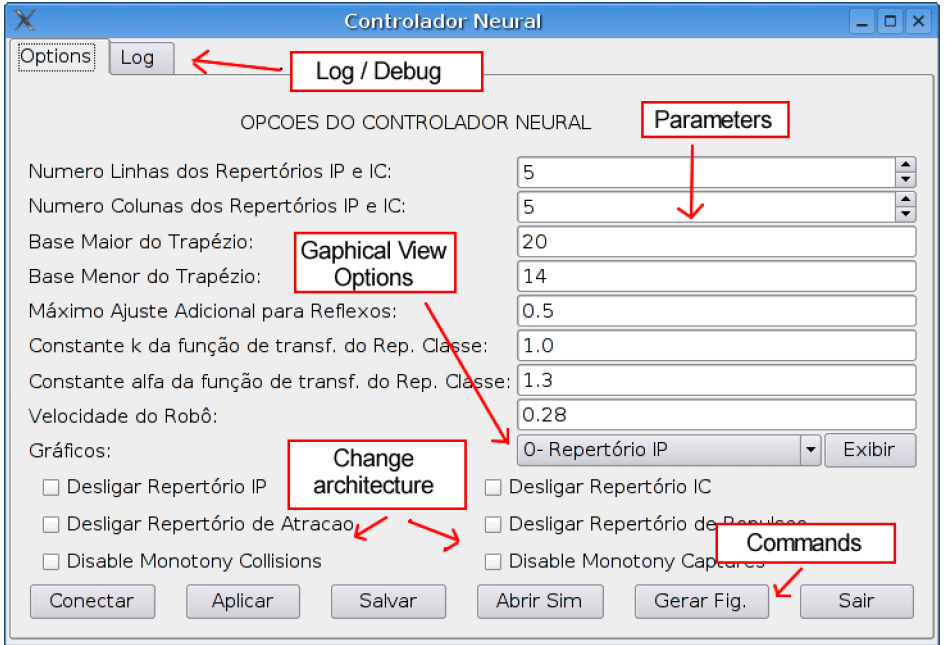
The graphical interface of CONAR is shown on the following figure. Parameters of the controller can be adjusted before the simulation and in real time; commands can be activated by clicking on buttons: connect to SINAR, apply parameters changes in real time, generate performance data and plots for recording in files, save neural networks state, exit simulation. Furthermore, some neural networks in the controller can be disabled in real time (so that it outputs null (zero)): IP, IC, RR and AR networks.
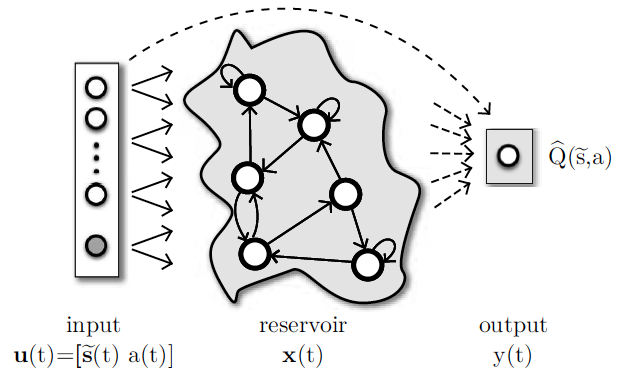
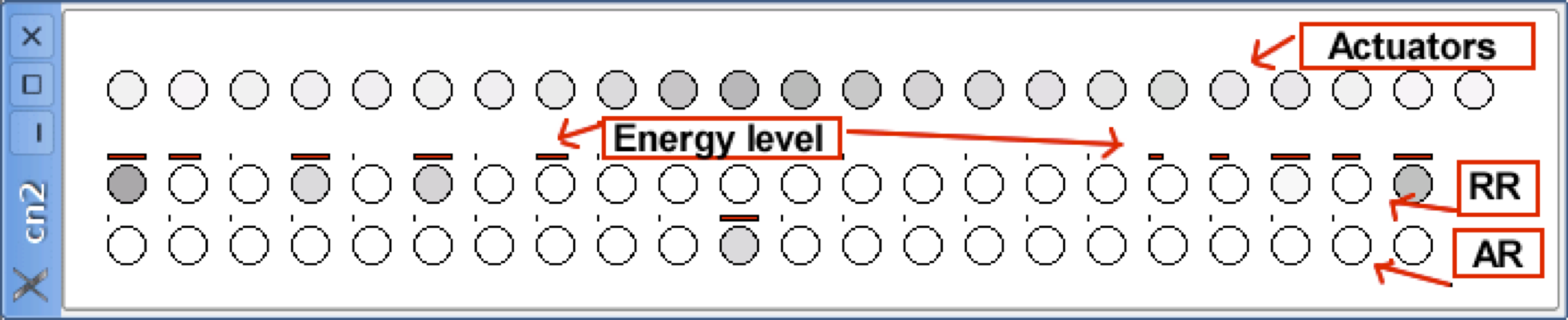
In addition, neural networks state can be viewed graphically in real time. In the following figures, a neuron is represented by a circle. In addition, the more black a neuron is, stronger is its output.

In above figure, it is shown a representation of PI repertoire neurons. A small red square inside a circle means that a neuron has already been winner during a learning event.
The next figure shows AR, RR and actuator neurons. The energy levels (degree of activity) of AR or RR neurons are represented by a thick line next to the respective neurons.
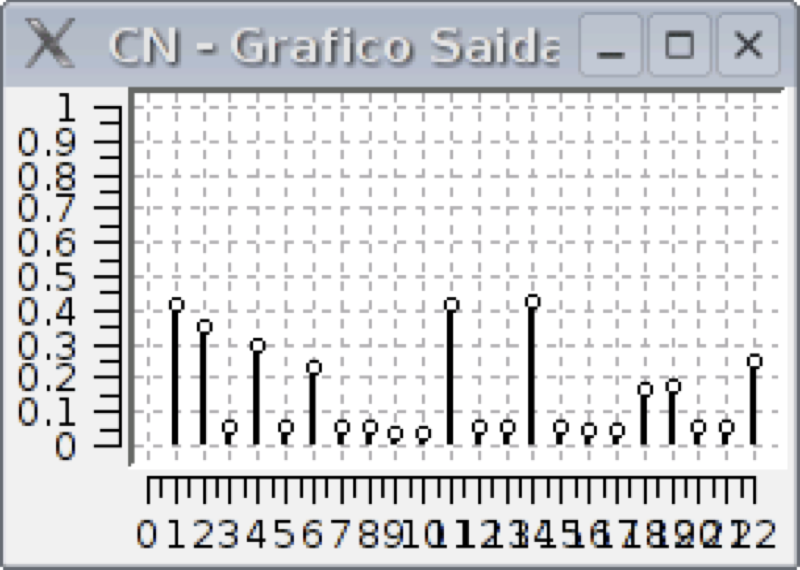
In following picture, it is shown the graphical representation of output of winner neurons in PI repertoire (each line represents the winner neuron output in a column: the first line corresponds to the first column and so on).
To see a video of a simulation run, check out this page: Reinforcement learning of robot behaviors
Related publications
- Eric Antonelo, Albert-Jan Baerveldt, Thorsteinn Rognvaldsson and Mauricio Figueiredo Modular Neural Network and Classical Reinforcement Learning for Autonomous Robot Navigation: Inhibiting Undesirable Behaviors Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), pp. 1225-1232 (2006)




- Eric Antonelo A Neural Reinforcement Learning Approach for Behavior Acquisition in Intelligent Autonomous Systems Master thesis, Halmstad University (2006)


- Eric Antonelo, Mauricio Figueiredo, Albert-Jan Baerlveldt and Rodrigo Calvo Intelligent autonomous navigation for mobile robots: spatial concept acquisition and object discrimination Proceedings of the 6th IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA), pp. 553-557 (2005)
- Eric Antonelo and Mauricio Figueiredo Autonomous intelligent systems applied to robot navigation: spatial concept acquisition and object discrimination Proceedings of the 2nd National Meeting of Intelligent Robotics (II ENRI) in the Congress of the Brazilian Computer Society (in Portuguese), pp. (2004)