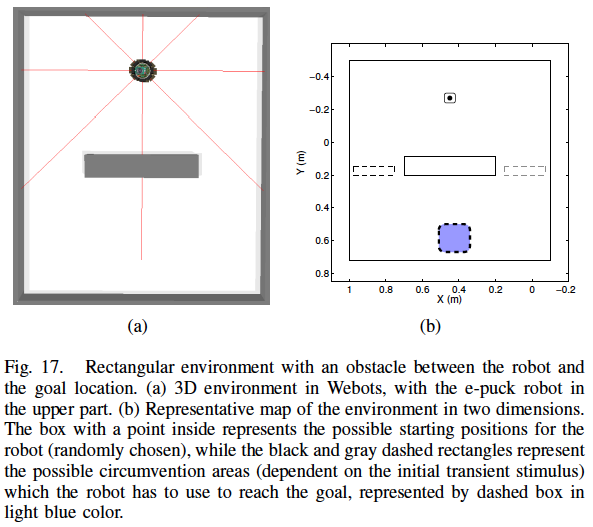
Autonomous robot navigation in partially observable environments is a complex task because the state of the environment can not be completely determined only by the current sensory readings of a robot. This work uses the recently introduced paradigm for training recurrent neural networks (RNNs), called reservoir computing (RC), to model multiple navigation attractors in partially observable environments. In RC, the RNN with randomly generated fixed weights, called reservoir, projects the input into a high-dimensional dynamic space. Only the readout output layer is trained using standard linear regression techniques, and in this work, is used to approximate the state-action value function. By using a policy iteration framework, where an alternating sequence of policy improvement (samples generation from environment interaction) and policy evaluation (network training) steps are performed, the system is able to shape navigation attractors so that, after convergence, the robot follows the correct trajectory towards the goal. The experiments are accomplished using an e-puck robot extended with 8 distance sensors in a rectangular environment with an obstacle between the robot and the target region. The task is to reach the goal through the correct side of the environment, which is indicated by a temporary stimulus previously observed at the beginning of the episode. We show that the reservoir-based system (with short-term memory) can model these navigation attractors, whereas a feedforward network without memory fails to do so.
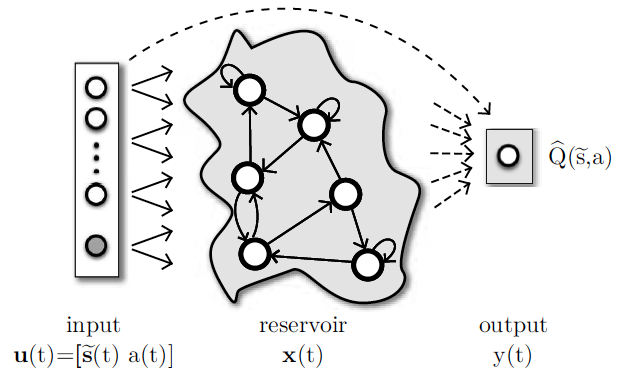
Reservoir Computing network as a function approximator for reinforcement learning tasks with partially observable environments. The reservoir is a dynamical system of recurrent nodes. Solid lines represent connections which are fixed. Dashed lines are the connections to be trained
Motor primitives or basic behaviors: left, forward and right.
A sequence of robot trajectories as learning evolves, using the ESN. Each plot shows robot trajectories in the environment for several episodes during the learning process. In the beginning, exploration is high and several locations are visited by the robot. As the simulation develops, two navigation attractors are formed to the left and to the right so that the agent receives maximal reward.
Title of Master thesis: A Neural Reinforcement Learning Approach for Intelligent Autonomous Navigation Systems
Classical reinforcement learning mechanisms and a modular neural network are unified to conceive an intelligent autonomous system for mobile robot navigation. The conception aims at inhibiting two common navigation deficiencies: generation of unsuitable cyclic trajectories and ineffectiveness in risky configurations. Different design apparatuses are considered to compose a system to tackle with these navigation difficulties, for instance: 1) neuron parameter to simultaneously memorize neuron activities and function as a learning factor, 2) reinforcement learning mechanisms to adjust neuron parameters (not only synapse weights), and 3) a inner-triggered reinforcement. Simulation results show that the proposed system circumvents difficulties caused by specific environment configurations, improving the relation between collisions and captures.
Video (inhibiting unsuitable cyclic trajectories through reinforcement learning):
The robot starts not knowing what it should do in the environment, but as times passes, we can see that it interacts with the environment by colliding against obstacles and capturing targets (yellow boxes). Each collision elicits an appropriate innate response, i.e., aversion. As more collisions take place, its neural network learns to associate obstacles (and its blue color) with aversion behaviors such that it can deviate from obstacles (emergent behavior). The same process occurs for target capture being associated with attraction behavior through learning. In the end, the robot can navigate the environment efficiently, capturing targets, effectively suppressing cyclic trajectories common to such reactive systems.
Video (robot cooperation; each robot trained with previous neural network architecture)
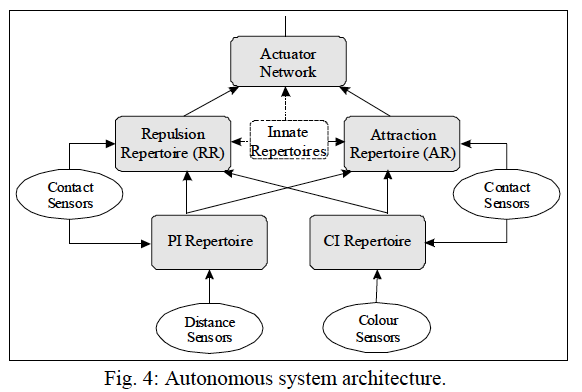
The intelligent autonomous system corresponds to a neural network arranged in three layers (Fig. 4). In the first layer there are two neural repertoires: Proximity Identifier repertoire (PI) and Color Identifier repertoire (CI). Distance sensors stimulate PI repertoire whereas color sensors feed CI repertoire. Both repertoires receive stimuli from contact sensors. The second layer is composed by two neural repertoires: Attraction repertoire (AR) and Repulsion repertoire (RR). Each one establishes connections with both networks in the first layer as well as with contact sensors. The actuator network, connected to AR and RR repertoires, outputs the adjustment on direction of the robot.